
Before the cases, a sketch of what we did. The methods appendix carries the details and the caveats.
The same speaker writes in two settings. On one side, heavily edited public language — speeches and addresses, often co-authored by staff, written to face an audience. On the other, less-curated material — personal letters, live press conferences, internal cables — where the figure has more room to be themselves. The registers overlap in the middle and diverge at the edges; the essay measures the divergence.
Each text chunk is scored on the five major personality dimensions — openness, conscientiousness, extraversion, agreeableness, neuroticism — by a language model. We aggregate per corpus and compare. The numbers reflect both real differences in how a person writes and a register-bias overlay from the model itself, which was trained on contemporary prose and applied here to 19th-century letters and diplomatic memos. See Methods §The instrument is borrowed.
A second pass counts hits against a small lexicon of classical virtues — prudence, justice, courage, temperance, truthfulness, magnanimity. This measures which virtues a public figure mentions, not which they hold, prioritise, or recommend that others cultivate. It’s a register signal about public moral talk, not a character claim.
Nagel opens with an observation that is as uncomfortable today as it was in 1978. The great modern crimes are not committed by private criminals. They are committed by people with offices, titles, and institutional authority. And somehow, that authority insulates them.
He calls it a “slippery moral surface.” The office-holder acts not as a private person but as a functionary — servant of something larger than himself. A secretary of defense, a president, a general. The institution gets between the person and their acts.
This is not merely a structural observation. It is a psychological one. The role reshapes the person. The language of duty, of national interest, of responsibility — these are not neutral. They gradually colonize the private moral vocabulary.
But Nagel adds something sharper. The exercise of power, he writes, is “one of the most primitive human feelings — probably one with infantile roots.” Holders of public power are personally involved to an intense degree, and probably enjoying it immensely. The office is not merely a mask. It is also a reward.
The question, then, is the size of the gap. Between the person who signs the letters and the person who gives the speeches. Between the voice off the script and the voice broadcast to the nation. Some public figures maintain coherence; others appear to fracture. The Nagel Index measures the size of that gap — not what it means.

Abraham Lincoln left remarkably few public speeches and remarkably many private letters. The contrast between the Gettysburg Address and a personal telegram to a grieving mother is not merely a difference in occasion — it is a window into whether the institution changed him.
His private correspondence is direct, warm, self-deprecating, and occasionally melancholic. There is no performance of presidential gravity in a letter to his wife. The syntax is looser; the concerns are personal.
The Nagel Index finds a medium overall gap score of 0.41, driven primarily by Conscientiousness and Agreeableness. But the raw score differences are tiny — never more than three percentage points on any trait. The effect sizes reflect how consistently the small shift appears across hundreds of text chunks, not how large the shift is.
This does not mean Lincoln was simple. It means he was consistent. The man who wrote “With malice toward none, with charity for all” in his Second Inaugural was the same man who signed condolence letters by hand. The institution did not transform him. This is the baseline.

Richard Nixon gave some of the most carefully constructed political speeches of the twentieth century. He also gave thousands of hours of unscripted live press conferences. The distance between those two archives — the rehearsed Nixon and the live Nixon, both still on the public record but built on entirely different rhetorical scaffolding — is what we measure here. The historical Nixon Tapes are not in this corpus; the gap below is the gap visible on the public record alone.
In the press-conference transcripts, Nixon is different. Not just in content — in texture. The vocabulary shifts from the lexicon of nationhood (america, spirit, peace, freedom) to the lexicon of operation (going, think, regard, course, concerned, matter). He sounds like a man running a machine, not leading a nation.
The Big Five gap is large and pulls in three directions at once. On Extraversion, the scripted Nixon was expansive, performative, rhetorically commanding; the unscripted Nixon was guarded, reactive, transactional. On Neuroticism, the scripted Nixon projected calm authority; the unscripted Nixon was anxious, suspicious, volatile. Conscientiousness moves furthest of all — the scripted persona was aspirational; the unscripted operator was loose, improvised, reactive.
Nagel would not be surprised. The institution did not insulate Nixon from his moral failures — it amplified them. The office gave his paranoia jurisdiction. The question of whether Nixon was corrupted by power or brought his corruption to power is, perhaps, unanswerable. The gap only tells us that the two Nixons were measurably different men.

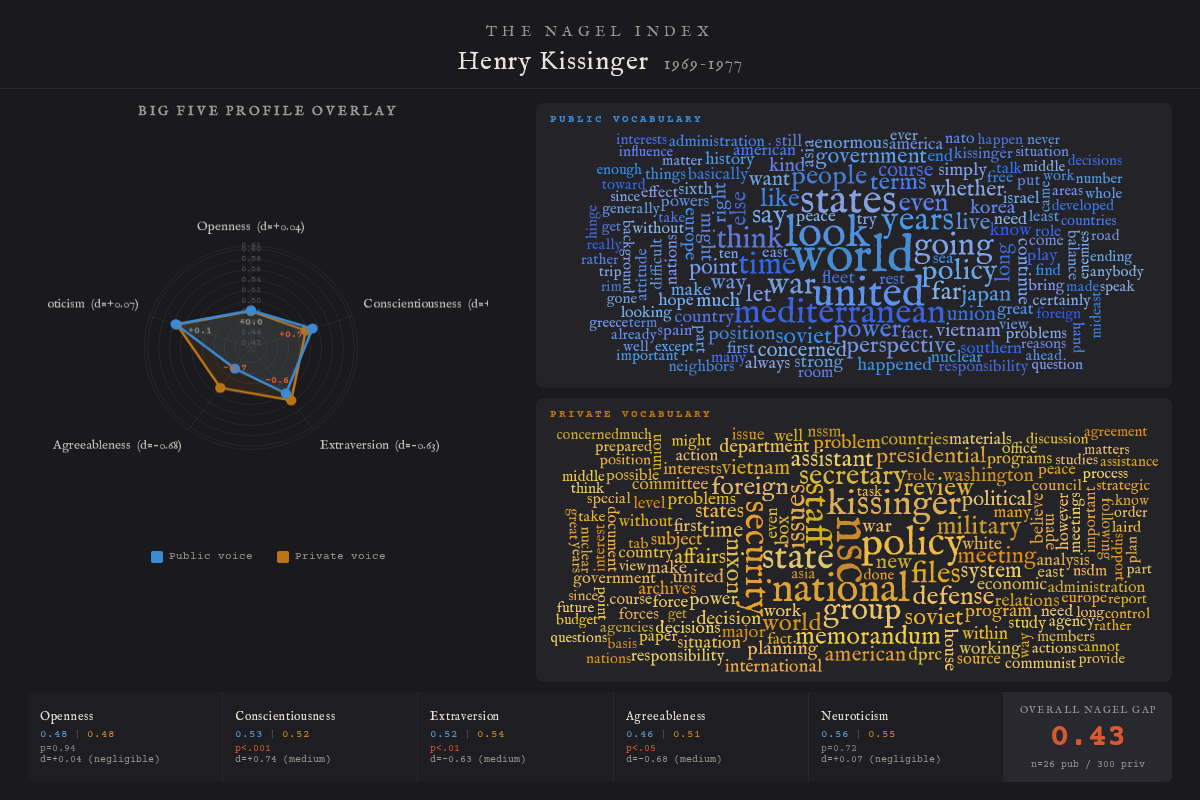
Kissinger is the hardest case. He appears in Nagel’s own essay — named as a man of high esteem despite the Christmas bombing of 1972 and “all that preceded it.” Nagel uses him as an example of exactly how the slippery moral surface works: the institution absorbs the act, and the man walks free.
His private vocabulary — secretary, policy, nsc, memorandum, files, staff — is the vocabulary of a system manager, not a statesman. In public he spoke of the world, of Mediterranean strategy, of the architecture of peace. In private he spoke of process.
The pattern splits cleanly. Agreeableness and Extraversion both drop substantially in private — the diplomat disappears, the public charisma turns out to have been a performance. Openness and Neuroticism barely move — the strategic intelligence and the emotional stability were the same in both registers, not performed for the cameras.
Kissinger the thinker and Kissinger the operator were the same person. Kissinger the public figure was a performance.
This is what makes Kissinger interesting to Nagel’s framework. He was not transformed by the office. He used it. The institutional role was a tool he wielded deliberately — the “slippery moral surface” was, for Kissinger, a known instrument. That is a different kind of gap: not fracture, but strategic distance.
Aristotle’s Nicomachean Ethics gave the West its first catalogue of character-virtues — practical wisdom, justice, courage, temperance, and their kin. Alasdair MacIntyre’s After Virtue (1981) argued that the modern world had lost the shared vocabulary to reason about those virtues and was left emoting about moral fragments.
This project cannot say whether Lincoln was courageous or Nixon was just. But it can measure the vocabulary: how often each figure’s public speech and private writing reaches for six virtues drawn from Aristotle and MacIntyre.


The Nagel Gap does not measure morality. It measures distance — the linguistic distance between the self that spoke to history and the self that spoke off the script: in correspondence, in internal memoranda, in live unrehearsed appearances. A small gap does not make Lincoln a saint. A large gap does not make Nixon uniquely evil. Both were capable of cruelty. But only one of them was linguistically the same man in both rooms.
Nagel ends his essay with a provocation. The plausibility of the institutional excuse, he writes, is “inversely proportional to the power and independence of the actor.” The more power you hold, the less the office can absorb. At the very top, the gap between the person and the role collapses — what remains is just the person.
The pattern in our data is consistent with that diagnosis. It is not a proof of it.
Five caveats the rest of the essay leans on but doesn’t always state out loud. Read this section as the load-bearing fine print — it bounds everything above.
Big Five scores come from Minej/bert-base-personality, a BERT model fine-tuned on contemporary English text. We apply it to 19th-century epistolary prose, mid-20th-century press-conference transcripts, and 1970s diplomatic memoranda — substantial domain shifts in every direction. Formal archaic prose almost certainly reads as more conscientious regardless of the writer’s character; transcribed live speech almost certainly reads as less so for the same reason. The reported numbers reflect a mixture of real personality differences and this register-bias overlay, and we have no way to disentangle the two from inside the data alone.
The data contains three distinct comparison shapes. The aggregate Nagel Score is meaningful within each shape but not across them — Lincoln’s 0.41 and Nixon’s 0.87 are not measuring the same thing.
We keep “public vs private” as the visual shorthand — the colour tokens, the toggle buttons, the data shape on disk — because reworking the data taxonomy is a separate project. But a careful reader should hold the gap type in mind. The “Gap type” column in the Methods table below labels each figure.
A presidential speech is co-authored by speechwriters; a diplomatic memo is institutional product; even a personal letter is written in awareness of posterity. The “private” voice is never only the speaker’s own. This essay does not attempt to isolate the speaker’s contribution from the genre, the room, or the collaborators — and a portion of every gap reported below could in principle be explained by those structural factors rather than personality.
The Nagel Index does not measure moral character, authenticity, or hypocrisy. It measures linguistic divergence between two text corpora associated with one person, scored by a model that has its own training-data priors. A large gap is consistent with at least four readings:
The descriptive evidence cannot adjudicate among these. The essay’s editorial framing leans toward (a) for narrative reasons; the data on its own does not require it.
Seven public figures, all American, almost all presidents, all male, spanning 1789 to 2009. Selection was driven by the availability of public-domain text archives in matched pairs of registers, plus canonical historical interest — not by any sampling principle that would generalise. Conclusions about leadership in general, about non-democratic contexts, about public figures outside the US presidential tradition, or about women in office are unsupported by what is here. A control sample of comparable non-public-figure pairs (academic public lectures vs personal correspondence, executive keynotes vs private email) would also be needed to know whether these gaps are anomalous or simply normal context-switching at scale.
The Nagel Index compares personality scores extracted from two text corpora per public figure. The exact comparison varies by figure — drafted oratory against personal letters, against live press, or against internal cables (see the Gap type column below) — and the aggregate Nagel Score is meaningful within each comparison shape but not across them. Everything below is drawn from open archives.
For each public figure we assembled two corpora from public-domain archives. Years refer to the figure’s time in office; campaign-era material is included where available. The Gap type column flags which kind of comparison each figure’s analysis is measuring — see the Limitations section for what each type does and doesn’t tell us.
| Public figure | Years | Public corpus | Private corpus | Gap type |
|---|---|---|---|---|
| Abraham Lincoln | 1861–1865 | Miller Center presidential speeches | Library of Congress — Abraham Lincoln Papers, Series 1 | I |
| Thomas Jefferson | 1801–1809 | Miller Center | Founders Online — presidential series | I |
| George Washington | 1789–1797 | Miller Center | Founders Online — presidential series | I |
| Richard Nixon | 1969–1974 | American Presidency Project — inaugurals & State of the Union | American Presidency Project — news conferences | II |
| George H.W. Bush | 1989–1993 | American Presidency Project | American Presidency Project — news conferences & interviews | II |
| George W. Bush | 2001–2009 | American Presidency Project | American Presidency Project — news conferences & interviews | II |
| Henry Kissinger | 1969–1977 | FRUS press conferences & public statements | FRUS memoranda, meeting records & private correspondence (HistoryAtState mirror) | III |
Gap type: I = Oratory ↔ Personal correspondence · II = Oratory ↔ Live press · III = Public statements ↔ Institutional cables. The aggregate Nagel Score is meaningful within each type, not across them.
Each document passes through a few mechanical steps: Unicode normalisation, removal of HTML and editorial footnotes, and a language check that drops anything not detected as English. Documents shorter than 150 words are skipped. The surviving text is cut into overlapping 400-word windows with 50% overlap — these are the chunks the personality model reads.
Every chunk is scored by Minej/bert-base-personality, a BERT model fine-tuned on the Big Five personality dimensions. Chunk-level scores are aggregated per figure into two distributions (public and private) and compared trait-by-trait with a Mann-Whitney U test and Cohen’s d effect size.
Cohen’s d expresses the distance between the two distributions in standard-deviation units — by convention, 0.2 counts as a small shift, 0.5 medium, and 0.8 or more large. The Nagel Gap Score shown on every dashboard is the mean of |d| across the five traits (we take the absolute value because we care how wide the gap is, not which voice scores higher on any given trait). The same small/medium/large bucket is then applied to that aggregate score, so two figures with very close aggregates — e.g. 0.41 and 0.43 — receive the same bucket label even when their per-trait patterns differ markedly. The narrative archetypes (Coherent, Fractured, Calculated) are read off the per-trait pattern, not off the aggregate.
Keywords are extracted using log-likelihood — Dunning’s G² — rather than raw frequency. The measure identifies words that are over-represented in one corpus relative to another, which is a far stronger signal of distinctive vocabulary than "what appears most often." For every public figure we compute two lists: the public voice versus the private, and the private versus the public.
The virtue-vocabulary scores come from a first-pass lexicon of six virtues drawn from Aristotle (Nicomachean Ethics) and MacIntyre (After Virtue): prudence, justice, courage, temperance, truthfulness, and magnanimity. Each virtue has 25–45 hand-picked marker words; per chunk we count exact-word matches and normalise by chunk length (hits per 1000 words). Correlations between virtue rates and Big Five scores are computed per figure and pooled across all seven, using Spearman’s rank correlation. The lexicon lives in the repo under data/virtues/lexicon.json and is explicitly treated as a starting point — it will be iterated on as the project’s understanding of MacIntyrean practice-virtues sharpens. Repeating the caveat from the Virtues act: this measures rhetorical emphasis, not moral character.
Each calligraphic split-face portrait is rendered by Google’s Gemini from a structured prompt that supplies the top 40 keywords per corpus. The four highest-ranking words per side are placed on forehead, cheekbone, jawline, and hair; the remaining words curve around the face as smaller text. The collar words — UNION / SEPARATION on Lincoln’s portrait — are synthesised by Gemini from the thematic arc of each word list.
A note on what those per-figure polar charts measure. Our lexicon counts how often a public figure mentions a virtue — reaches for the word justice, the word courage, the word prudence. It does not measure whether they hold the virtue, prioritise it in their own life, or recommend that others cultivate it. The signal is rhetorical, not psychological: which moral terms a public figure deploys, in which setting. Placing this register signal on the same page as the Big Five is a deliberate provocation, not a synthesis — the two come from different conceptual traditions, and vocabulary is not character.
With that said, the pattern is worth naming. Lincoln keeps his virtue vocabulary roughly steady from public to private, and actually raises truthfulness and temperance in his correspondence. Nixon’s private voice drops nearly every virtue by a clear margin — truthfulness, magnanimity, courage all fall sharply, while prudence (strategic caution) is the only term that rises. Kissinger sits in the technocratic flat line he occupies on every other measure: few virtues in either register, a diplomat among process words.
When we correlate virtue-vocabulary rates with the Big Five at the chunk level across all seven public figures (n ≈ 3000 chunks, Spearman ρ), one result dominates: every virtue correlates positively with Conscientiousness, and nothing else consistently. Temperance tracks Conscientiousness most tightly (ρ ≈ 0.19, p < 0.001). The other four traits — Openness, Extraversion, Agreeableness, Neuroticism — tilt slightly negative across the board, which is what register, not character, would predict: formal moral language reads as structured rather than spontaneous, personal, or expressive.
What this adds to Nagel’s argument is modest. The office demonstrably shapes how a public figure talks about virtue — the rhetorical register drifts with the institution. Whether it shapes whether they possess virtue is a question our vocabulary can indicate but not settle. The interesting case is the one where both the personality gap and the virtue-vocabulary gap move together: Nixon, whose private self loses not only measurable Extraversion but almost every moral term our lexicon looks for.