
If data is the new oil, then getting and enriching data is like fracking and refining it, at least in the case of textual data. Our previous post introduced the basic idea of data gathering and annotation. Now we help you with the strategies and tools you can employ to fuel your algorithms.
Both data gathering and annotation are complex enterprises. It should be carefully thought over who you trust to carry out these tasks and what tools you employ. Let’s see our tips on data gathering and annotation strategies and tools.
Data gathering options
In-house solution
As we mentioned in the first part of this series, data gathering should be think of as a process. That’s why most of our clients want to build their in-house capabilities. This way they can be flexible and react very fast to changes in the requirements. If one goes for the in-house solution, there are plenty of tools to use. Our favorite one is Scrapy, the lingua franca of scraping and crawling the web. It is a mature and well-maintained Python framework with excellent documentation.

You can learn the basics of Scrapy and web scraping within a short time. A few minutes of googling will provide you with excellent tutorials. Our favorite resource is Mitchell’s Web Scraping with Python.

If your company is not a Python shop and/or you are interested in other technologies, take a look at Apache Nutch and sparkler, which is a Spark-based crawler.
No matter which tool you use, you’ll have to manage your scrapers and the infrastructure around them. Your devops team should be prepared for the needs! You can go for cloud solutions too, e.g. Scrapinghub’s Scrapy Cloud.
Outsourcing
Web scraping and crawling seems to be an easy task. Google has already done it for ages! That’s just partly true. Google is able to do it by employing an army of developers and running probably the largest hardware infrastructure of the world. However we learned from our mistakes that scraping is not that simple! We’ve already discussed the problem of modern JavaScript frameworks and locked sites. There are sites that ban particular IP address after a certain amount of requests, so it is a good tactic to rotate your IP address. Sites are constantly changing these days, so scrapers should be maintained if one needs up-to-date data.

If you want to get your data from more sources, and you want to update your data on a regular basis, you need to manage your scrapers. There are companies specialized in such tasks! Scraping and crawling are highly specialized skills and most companies don’t need employers with such skills all the time. Chances are high that the easiest way to collect your data is not to compete with such specialized companies to hire developers, but becoming their client. Of course, there are plenty of firms which offer similar solutions. To find the most suitable one, don’t forget that Google is your friend!
Crowdsourcing, employing an army of developers
As another option you can look for a specialist on big freelancer sites who can write or update a specific scraper for you. This is the crowdsourcing solution. By splitting up data gathering into small tasks, you can dramatically reduce your costs. You can group the sites into workpackages, or you can treat one site as one job and post them on freelancer sites. However, this option gives you more administrative work. You need to manage your contractors and constantly check the quality of their work. Also, this presupposes a robust architecture for managing and deploying the scrapers/crawlers.
Annotation options
The importance of annotation
Why do we need annotation? The industry usually uses supervised algorithms, which needs labeled or annotated data. Raw data should be cleaned and labeled before it can fuel any training algorithm. When you read about the 80% rule in data science, the articles usually tell you that 80% of each project spent on collecting, cleaning and reshaping data. In case of projects involving textual data, this is not true. The reality suggests that even more time is needed to get your data right and annotated. We would say that 90-95% of the time should be devoted to gather, clean, transform and annotate your data. Sometimes even more.
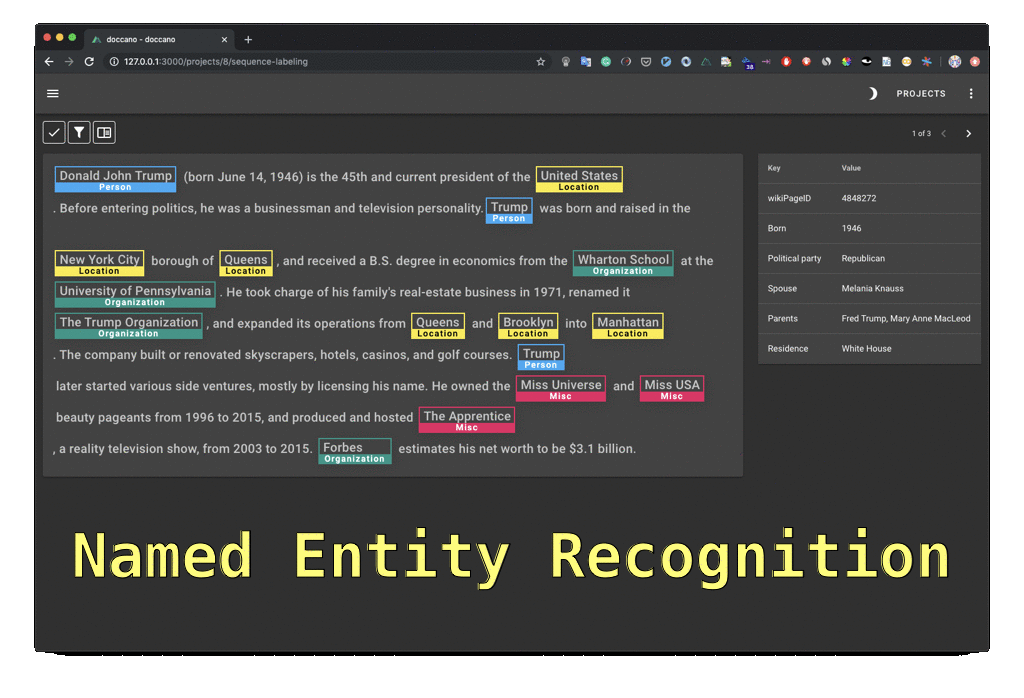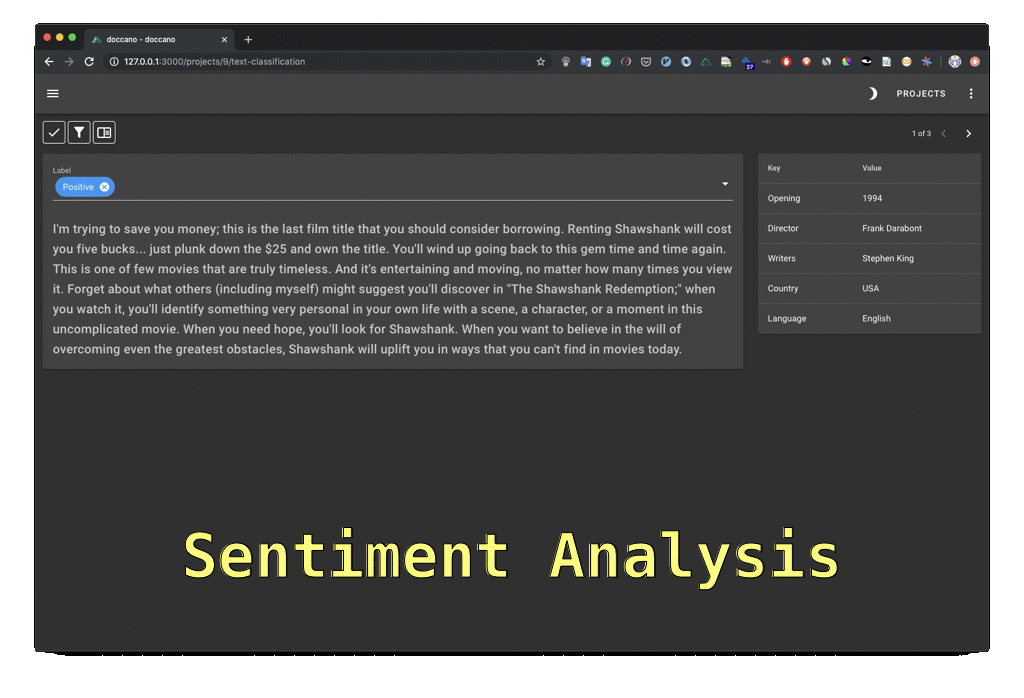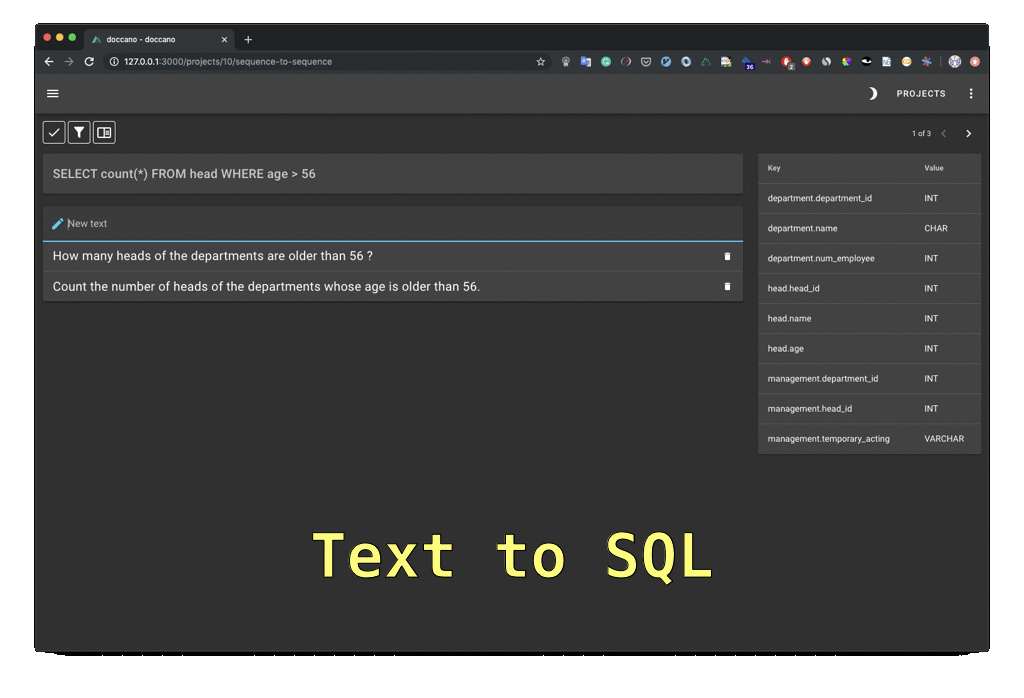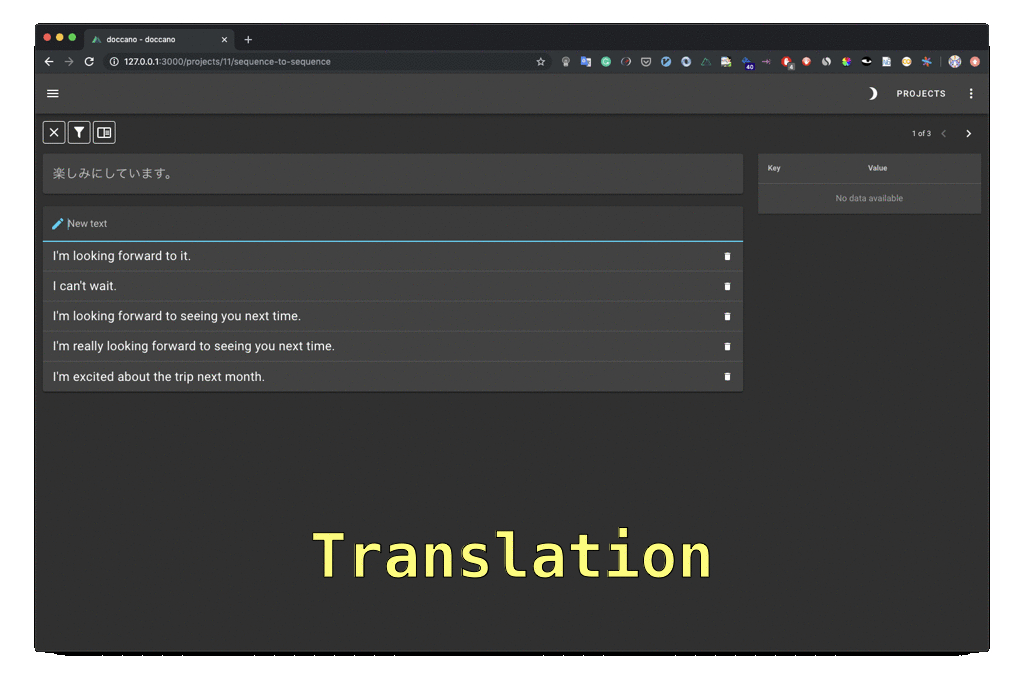
Regarding textual data, annotation can be carried out at different levels. A label can be given either to the whole text (e.g. its genre, like criminal news), or to each sentence (e.g. the sentence expresses positive or negative sentiment), or to the words/phrases (e.g. Named Entities like names of persons, firms, institutions, etc.) The more data you have, the better your chances are to build a good model on it.

Source: https://www.reddit.com/r/step1/comments/dx6f8t/mistake_for_those_who_recently_started_preparing/
A good annotation software makes possible to upload texts in raw format, manage annotators, and define annotation, i.e. what kind of labels can annotators assign to texts or words. Annotators should be prepared for their tasks, which means that they need some training and a guideline at hand during their work. It is a good quality assurance practice to annotate every item, or a a certain percent of the whole corpus with at least three annotators and measure their agreement. One can easily think that annotation is a tedious and very time consuming task – and it is! However, thank to recent advances in the field of active learning, the costs and time horizon of annotation tasks can be dramatically reduced. (Read more on this topic in Robert Munro‘s book, Human-in-the-Loop Machine Learning). Considering your annotation strategy, you have to keep in mind all these issues! No matter whether you build-up your in-house solution, or run your annotation tasks on crowdsourcing sites or you hire a specialist company.
In-house solution
If you’d like to keep the data annotation task within your organization, you’ll need a good annotation tool. You can find free, open source tools like doccano. It doesn’t support active learning out of the box, so it is a good task for your Python developers to integrate it with an active learning library. The creators of Spacy made Prodigy, an annotation tool that supports active learning. It’s not free but it is reasonably priced.

Now you have data and an annotation tool, so you are ready to plan your annotation task. Read Natural Language Annotation for Machine Learning by Pustejovsky and Stubbs to learn more about it. Keep in mind, annotation is not a black art, but you need experience to plan and execute it correctly.

Crowdsourcing
If building in-house competencies is not a viable option, it’s worth considering crowdsourcing. You still need someone who describes the tasks, manages the annotation process and takes care of quality issues, but you don’t have to deal much with annotators. Tools, like Amazon’s Mechanical Turk allows one to slice tasks into small micro-tasks, and present them to remote workers via a platform. You don’t have to deal with hiring workers and putting them on your pay-roll, since the crowdsourcing site manages these tasks. Usually, you can set some sort of experience limit, so you can select among applicants on the basis of their expertise. It is a good practice to provide workers with good instructions and a trial task before accepting their application.
Crowdsourcing can be extremely fast, and if it is done wisely, the results can be of good quality for a relatively low price. However, the more complex the task is, the harder it is to find good workers. Also, crowdsourcing raises ethical and methodological questions both for academia and for the industry. Also, it can rise privacy issues too.
Outsourcing
There are data annotator companies that offer solutions to the problems of crowdsourcing. Such companies employ (permanently or for a limited time) lots of annotators, so their people are well trained, precise and paid better than workers of crowdsourcing sites. They can be of help in planning the annotation task too. Also, such companies are aware of the legal environment, like GDPR. The complete outsourcing of the annotation task to a company seems to be an expensive step, however sometimes it is the best way to get data. The market of such companies is huge and it is relatively easy to find one, you can go for a global provider (like Appen, for example) or look for local companies in your region.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Do you need help? Hire Us!
Considering such options can be daunting. Don’t panic! Contact us, and we’ll help you to make the right decision so your algorithms will be fueled by the finest oil.
Sources
The header image was downloaded from the following link: https://www.flickr.com/photos/sfupamr/14601885300
Make a one-time donation
Make a monthly donation
Make a yearly donation
Choose an amount
Or enter a custom amount
Your contribution is appreciated.
Your contribution is appreciated.
Your contribution is appreciated.
DonateDonate monthlyDonate yearlyDo you like our visualizations? Buy them for yourself!
Visit our shop on Society6 to get a printout of our vizs.


This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.